Anomaly Detection (AD)¶
General Description¶
Applying AIAD enables the user to obtain comprehensive anomaly detection, focusing on evaluating the machine as a whole and at component level. Relevant variables, associated with key component features, will be identified, followed by the extraction of these features from the measured time series data. Then, unsupervised learning methods will determine the boundaries between what is to be considered and anomaly or not. Finally, these models will be used with new fed data to obtain a list of the anomalies detected in the machine during working conditions. This will enable the AIDEAS Anomaly Detector to accurately assess the detection of anomalies in the individual components and the overall impact on the machine performance in terms of anomalies within the context of AIAD. This solution can serve as a trigger for AIAC solution, in case a compensation needs to be made after the anomaly has been detected.
Usage Viewpoint¶
Use Model¶
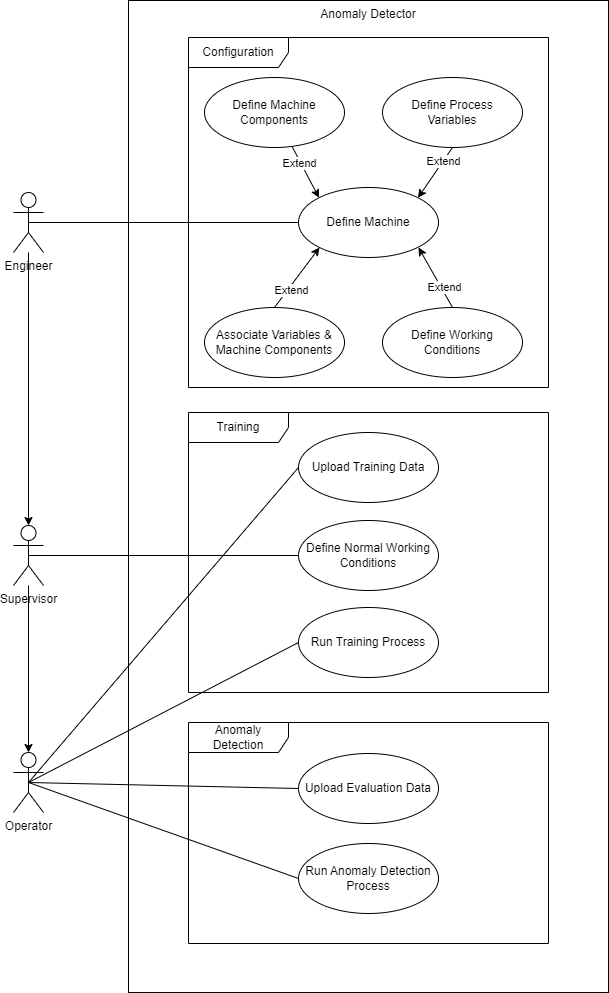
Description¶
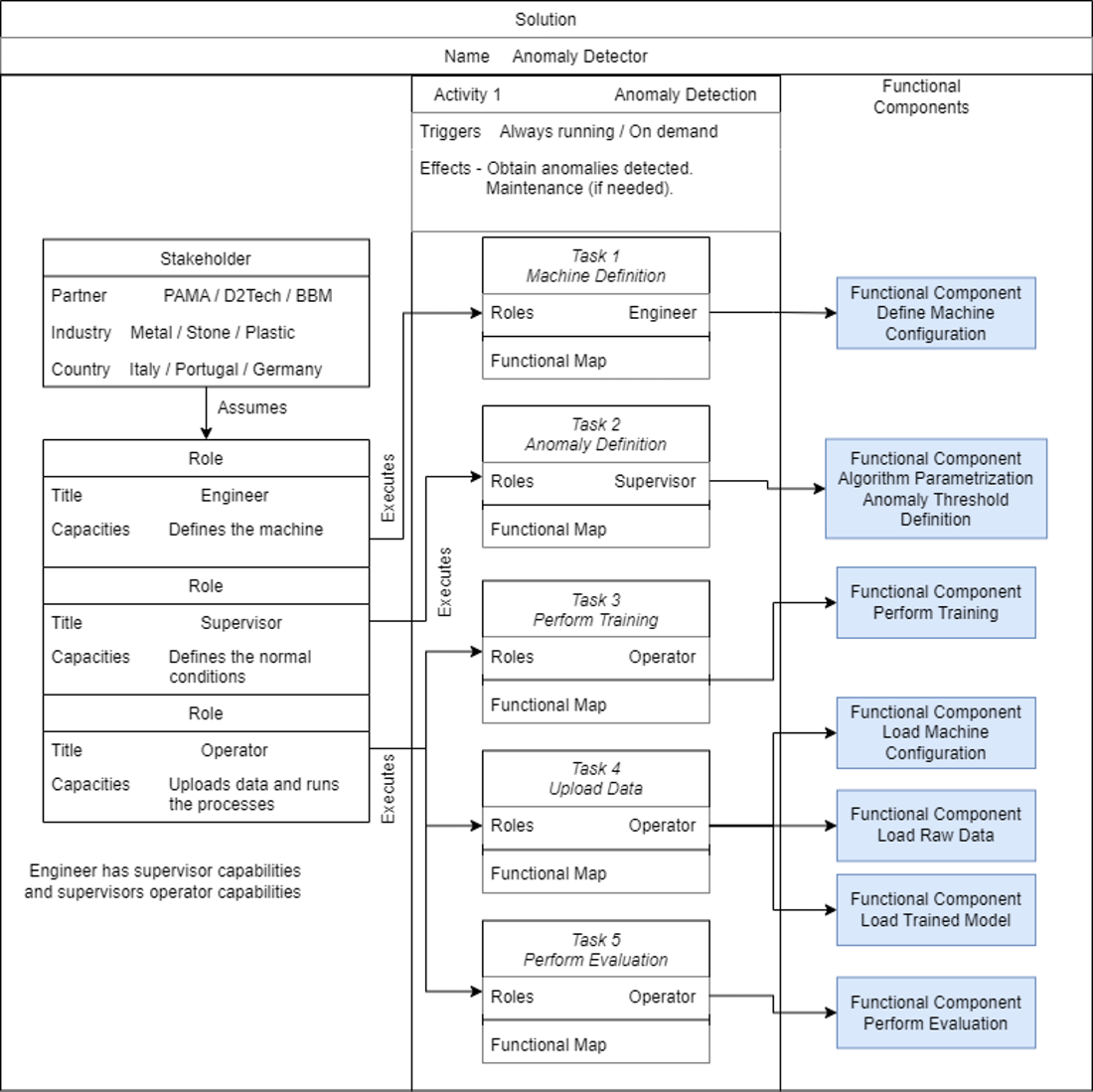
An initial step of configuration is necessary to define the scope where the Anomaly Detector will be deployed, the machine to be monitored. For this task an engineer is required, so the machine is defined properly, these are the required tasks: First of all, the different machine components will be defined, that is, the different relevant zones of study in which the machine can be divided. Then, the different process variables present, such as temperatures, currents, pressures, speeds, … And finally, the association between process variable and components, meaning, which variables affect directly to which component. As an additional step, it may be necessary to define working conditions such as which tool is currently being used, the different processes performed or define the conditions that indicate that the machine is not idle or working.
Once the machine definition is completed, a model of the machine will be trained, for this task the supervisor and the operator have to work together. The supervisor will define the normal working conditions for each process variable of study, that is, defining the thresholds in which the machine has a proper behaviour. In order to train the model, a dataset is needed, obtained from a file or from a DB, as well as to define the desired algorithm and its parameters. Finally, the training process can be performed.
As the last step, the anomaly detection process will be performed by the operator. This process is a continuous task, where anomalies, if existing, will be detected. The solution will give a list of the last anomalies detected for the whole machine, as well as a list of the last anomalies detected per component.
Every task performed by the operator can be performed by the supervisor and so on for the higher hierarchy users.
Configuration¶
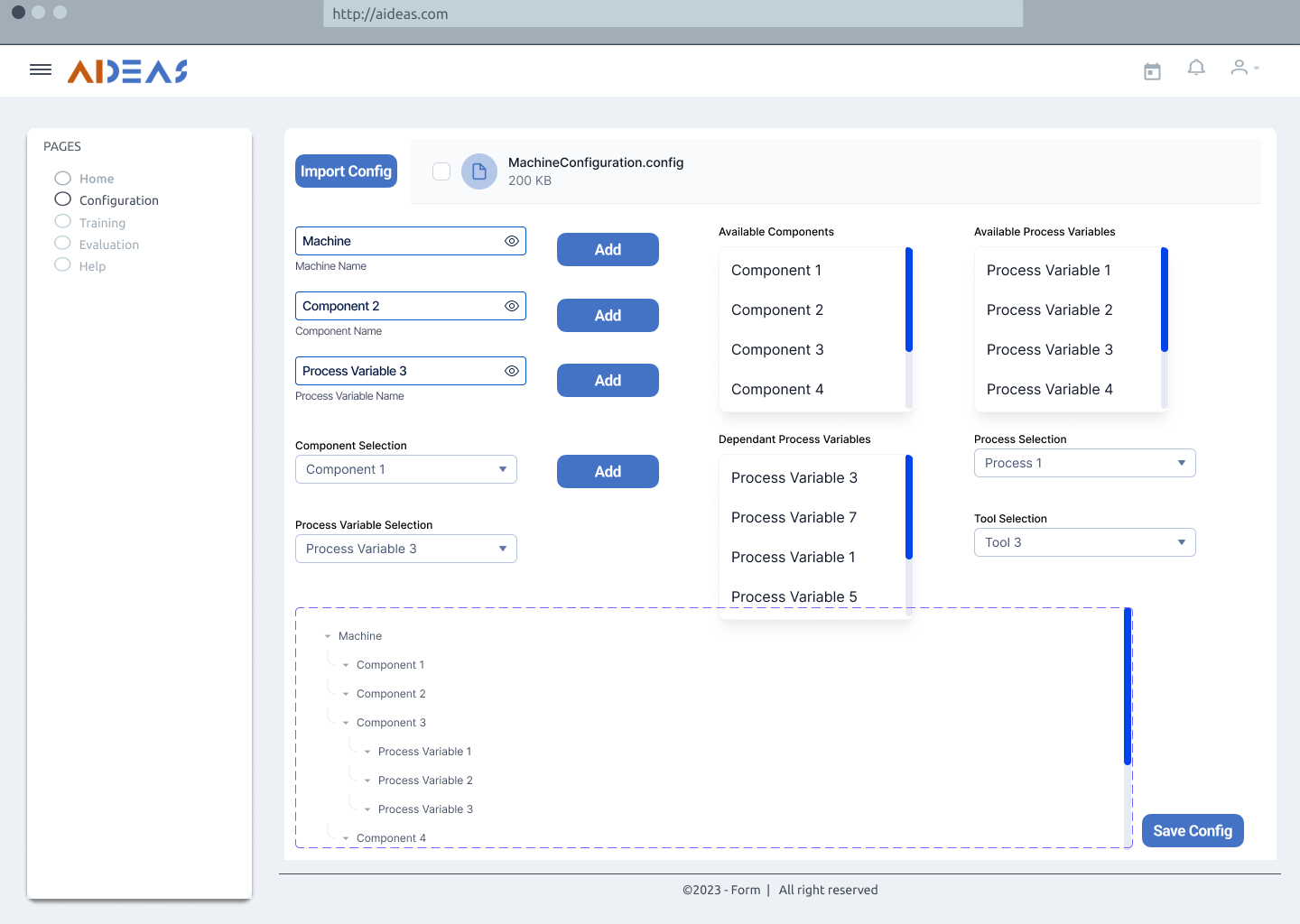
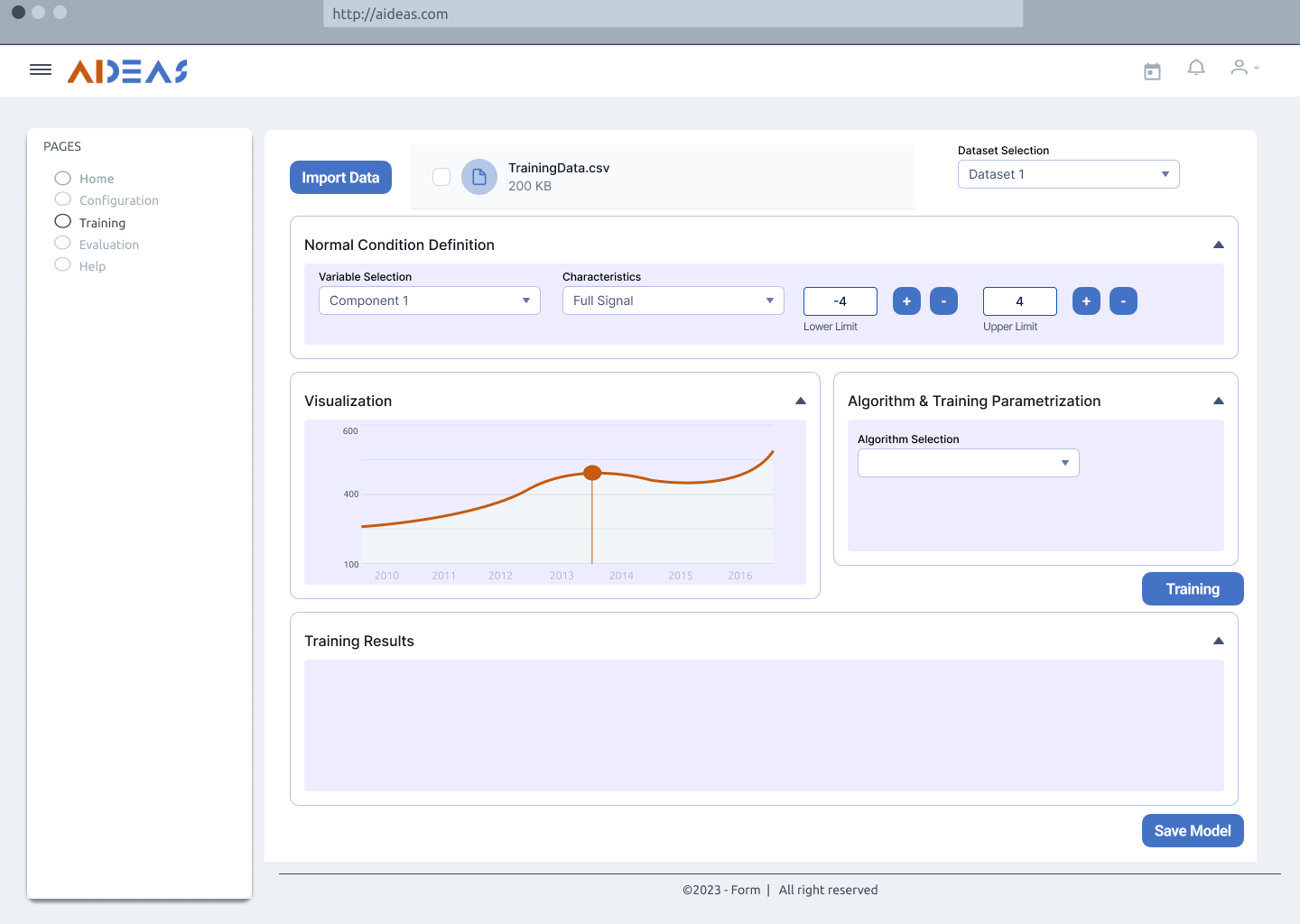
Training Parametrization¶
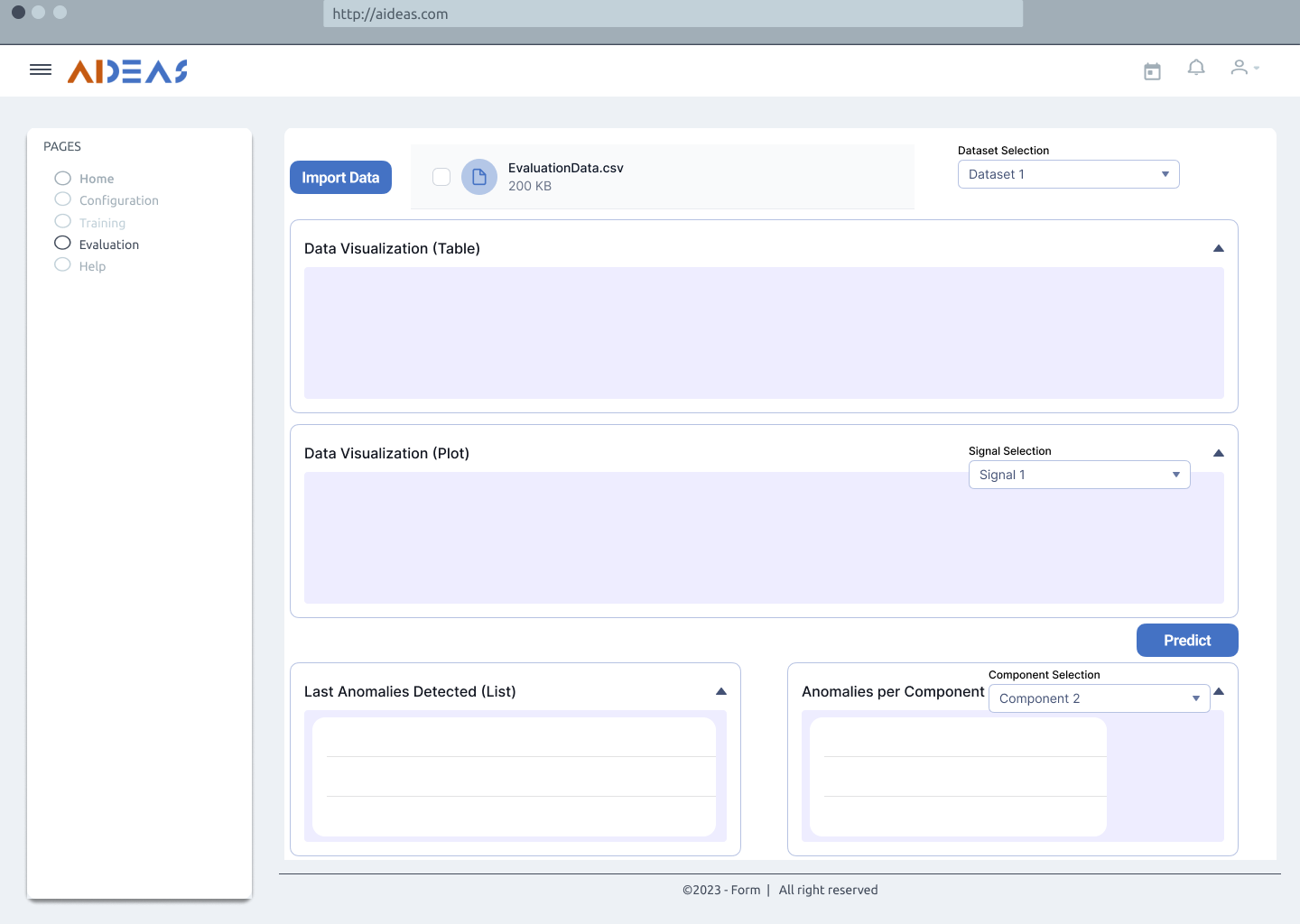
Evaluation¶
Usage activity diagram¶
The following image demonstrates the interaction between the different tasks and roles. No pilot distinction is made, as these are the same independent of the use case. This diagram illustrates the dynamic flow of interactions, offering a representation of the activities executed by the solution providing a clear understanding of the activities executed using the AIAD solution.
Functional Viewpoint¶
Functional diagram¶
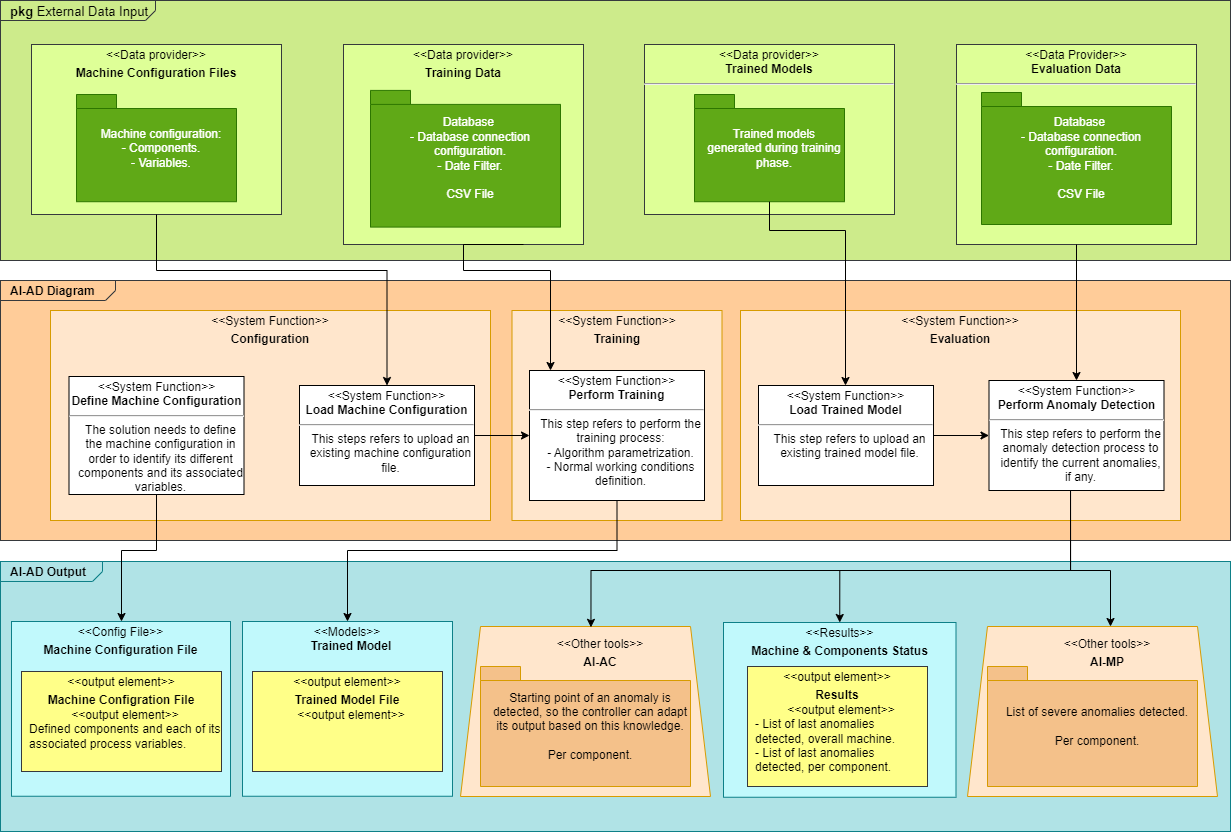
Functional description¶
What: The main feature of this component is to detect if the machine, in which is deployed, or in any of its components an anomaly has been detected. This anamoly detection could be computed in pseudo real time.
Where: Platform Tier
Why: To detect possible anomalies in the process
Who: Process Engineer. C&I Engineer. Operator.
Input and output data for each component¶
Define Machine Configuration¶
Inputs:
Machine: Machine in which the solution is deployed.
Components: Every subset of elements that define the machine.
Variables: Each process variable that exist in the use case. Variables such as: speed, current, pressure, flow, temperature, …
Dependencies: Relation between components and process variables. They define which process variables have a direct effect in a specific component.
Tool: If there are different tools
Process: If there are different processes carried out by the same machine.
Outputs:
Machine configuration file: Its extension may vary depending on the machine in which will be deployed. Its format will be standardized independently of the solution, and it could be a JSON or xml file.
Load Machine Configuration¶
Inputs:
Machine configuration file generated.
Outputs:
Machine configuration viewed as a hierarchy tree with the following levels:
Machine.
Component.
Process Variable.
A List with the relationship between component and variables.
A list of the different tools used.
A list of the different processes.
Perform Training¶
Inputs:
Training data: Set of data gathered from a database or uploaded from a csv file.
Algorithm selection and parametrization: The desired algorithm must be selected, from a list, and parametrized.
Working conditions: Normal working conditions must be defined with a set of thresholds in order to classify the anomalies.
Outputs:
Trained Model: Once the training process has finished, a model could be downloaded from the frontend to be used as an input for the anomaly detection process. Model file extension is yet to be defined.
Load Trained Model¶
Inputs:
Trained model file generated during training phase.
Outputs:
Trained model statistics.
Perform Anomaly Detection¶
Inputs:
Evaluation data: Set of data, different from the training data, gathered from a database, periodically, or uploaded from a csv file.
Outputs:
Anomaly detection results: The output may vary depending on the consumer of the results generated with this tool:
Machine in which the solution is deployed: a list of the last anomalies detected will be displayed as well as the last anomalies detected per component. Data could be written directly to a database or could be downloaded by the user from the frontend.
AI-AD: the detected anomaly starting point will be given when an anomaly is detected so the controller can use this knowledge in order to adapt its output. Anomalies starting points will be given per component.
AI-MP: a list of severe anomalies detected will be given. Also, these indicators will be given per component.
Software requirements¶
Software Component |
Description/Role |
Required Version/Configuration |
Dependencies |
|---|---|---|---|
Linux OS or Windows OS |
Operating system needed to use the tool |
Ubuntu 22.04 / Windows 10 Pro |
N/A |
Docker |
Build, share and run containers |
latest |
N/A |
Lifecycle¶
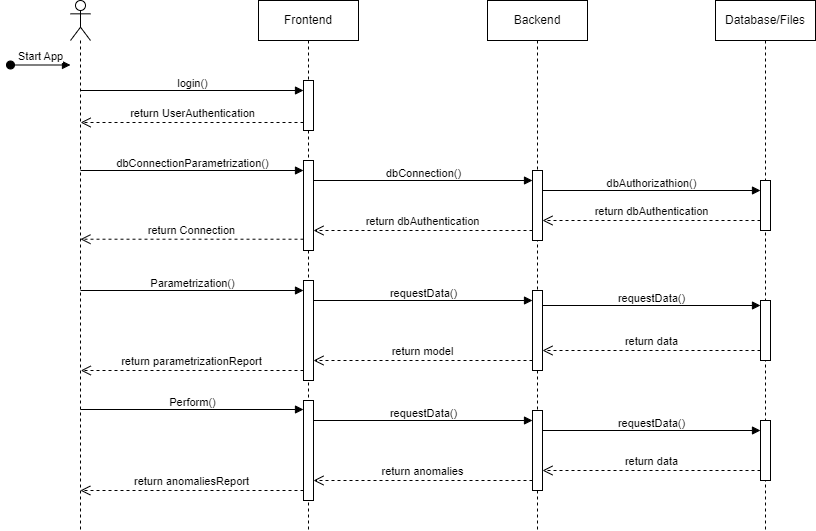
This sequence diagram illustrates the flow of interactions between the User, Frontend, Backend and Data/Files objects during the main processes. Login into the AIDEAS platform, parametrize a connection to an external database, parametrize the anomaly detection and perform it.
Objects¶
User: Represents the user interacting with the application.
Frontend: Represents the user interface and the presentation layer.
Backend: Represents the application logic and the server layer.
Database/Files: Represents the data or file storage layer.
Implementation Viewpoint¶
Description of implementation Component:¶
AI-AD is a toolkit for anomaly detection at both machine and component levels.
Technical Description of its Components:¶
Dependencies:
Development Language: - Python.
Libraries: NumPy, Pandas, SciPy, Keras, Py Torch, TensorFlow.
Container: Docker.
Database need: MongoDB.
Interfaces:
User Interface: Yes, REACT.
Synchronous/Asynchronous Interface: RESTful APIs.
Network/Protocols: HTTP/HTTPS.
Data Repository: MongoDB
Requires:
Other AIDEAS Solutions: AI-CE (could be used as a trigger to know when an anomaly is first detected)
Solution architecture¶
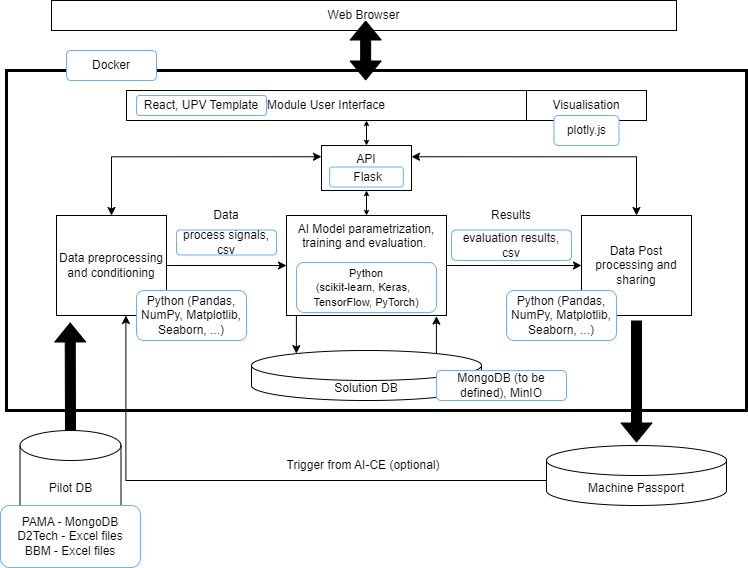
AI-AD’s backend will be developed in Python using the most common libraries used in data science and machine learning, such as: NumPy for array and matrix processing, Pandas for data analysis and processing and SciPy, Keras, Py Torch and TensorFlow for training and evaluating machine learning models. AI-AD’s frontend will be developed in REACT, which is a JavaScript library, Redux will be used to manage the application state. Both, backend and frontend, will be communicated over a RESTful API using HTTPS protocols. The API could be tested using tools such as Postman. Docker, which is a platform to build, deploy, run and manage containers, will be used to package everything the software needs to run.