Machine Synthetic Data Generator (MDG)¶
General Description¶
The primary objective of this tool is to synthesize data for training the optimization modules in AIMDO. Consequently, AI solutions will be made accessible for shorter time series and lower volume productions, with a reduced need for resources to train the relevant AI algorithms. The data will be primarily generated through artificial means, utilizing digital twins and simulations. The first step involves determining suitable samples from the parameter spaces. Subsequently, the automation of the simulation processes must be established, ensuring that the necessary computer resources are available for executing the automated simulations. Additionally, a monitoring system will be developed to oversee the simulation data space, tailored to the specific optimization modules. Real-world and historical data from pilot customers will also be incorporated to enhance the training data tensor. This inclusion is particularly important to guarantee unbiased training data, enabling the optimization modules to draw from a balanced data pool.
Usage Viewpoint¶
Use Model¶
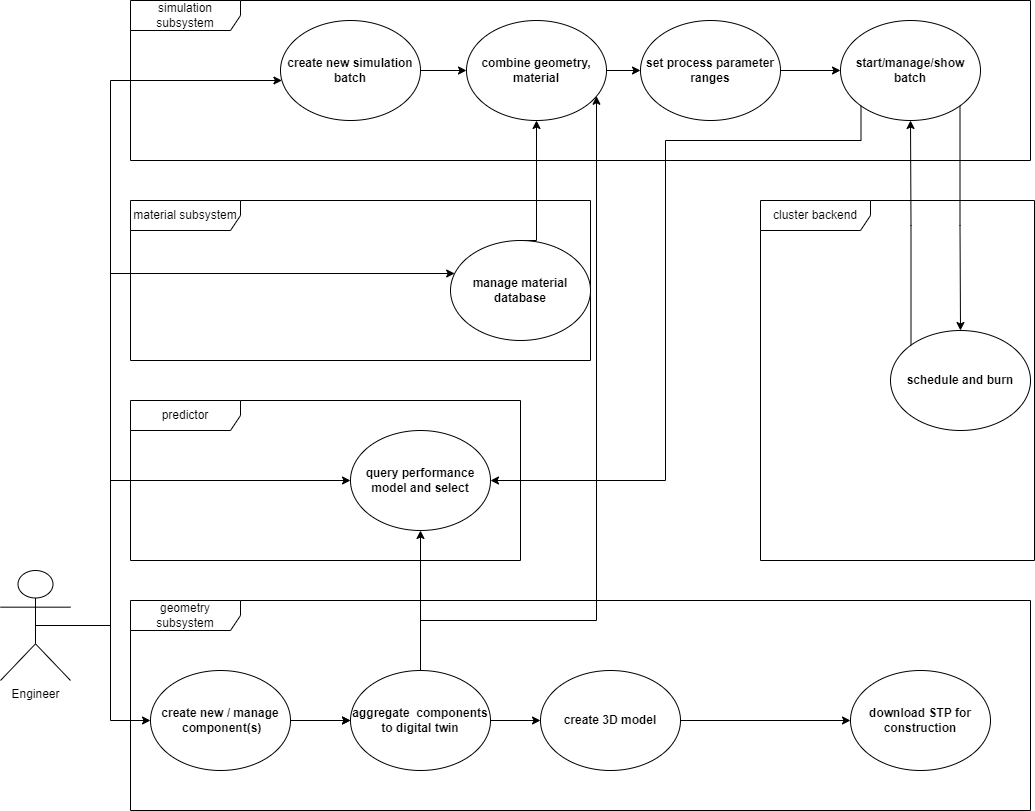
Description¶
Our system facilitates user interaction through four interconnected layers, each involving stored project data. While there is a natural workflow, each layer can be accessed independently.
The first layer is the geometry subsystem, where users create the digital twin of the machine. They utilize data from rheological or other external measurements to define fluid and solid material properties. This process involves automatically constructing Computer Aided Engineering (CAE) solids, which provide initial visuals that are combined to form the digital twin.
Once the digital twin is assembled, users proceed to the 3D modeling layer, where they finalize the model. This completed model can be visualized, saved, modified, and exported for real-world construction. Typically, at least one full simulation cycle is performed at this stage.
Simultaneously, the prediction subsystem offers AI inference capabilities on the 3D model. It incorporates pre-trained performance models that provide real-time estimations of the prototype’s performance, offering valuable insights to the user.
Users also have the flexibility to define material properties used in viscosity terms for the numerical solver. These properties are eventually combined with the digital twin and other process data in the simulation subsystem.
Finally, the system enables the creation of simulation batches that can be queued and processed by the compute grid. This detailed and layered process ensures a comprehensive interaction between the user and the system, ultimately leading to the development of a precise and predictive digital twin.
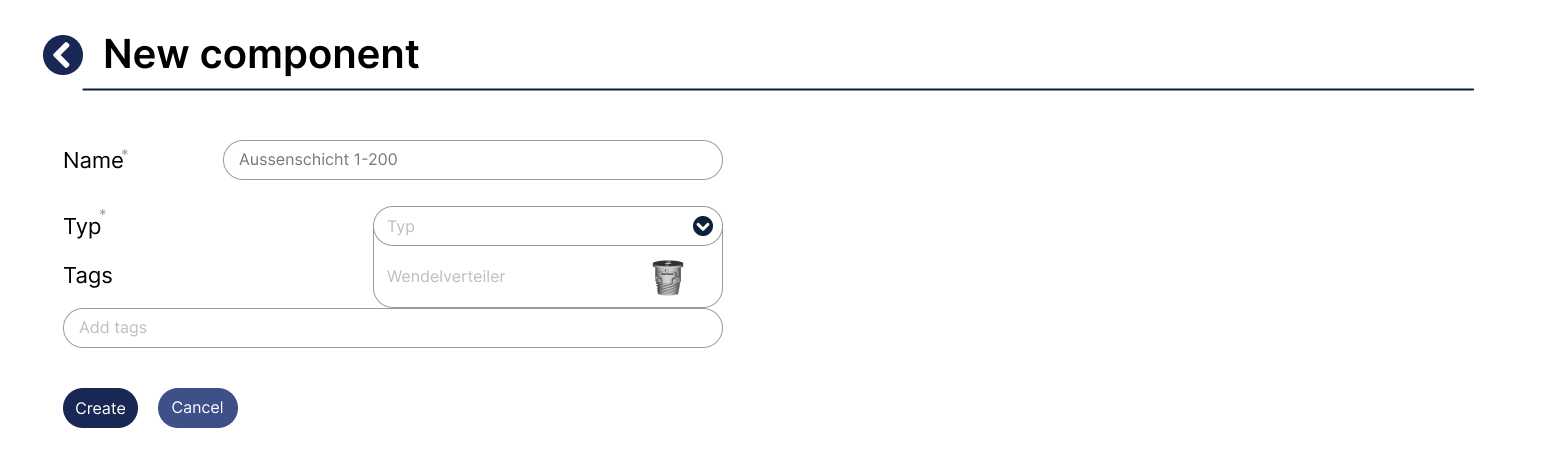
Insert new component¶
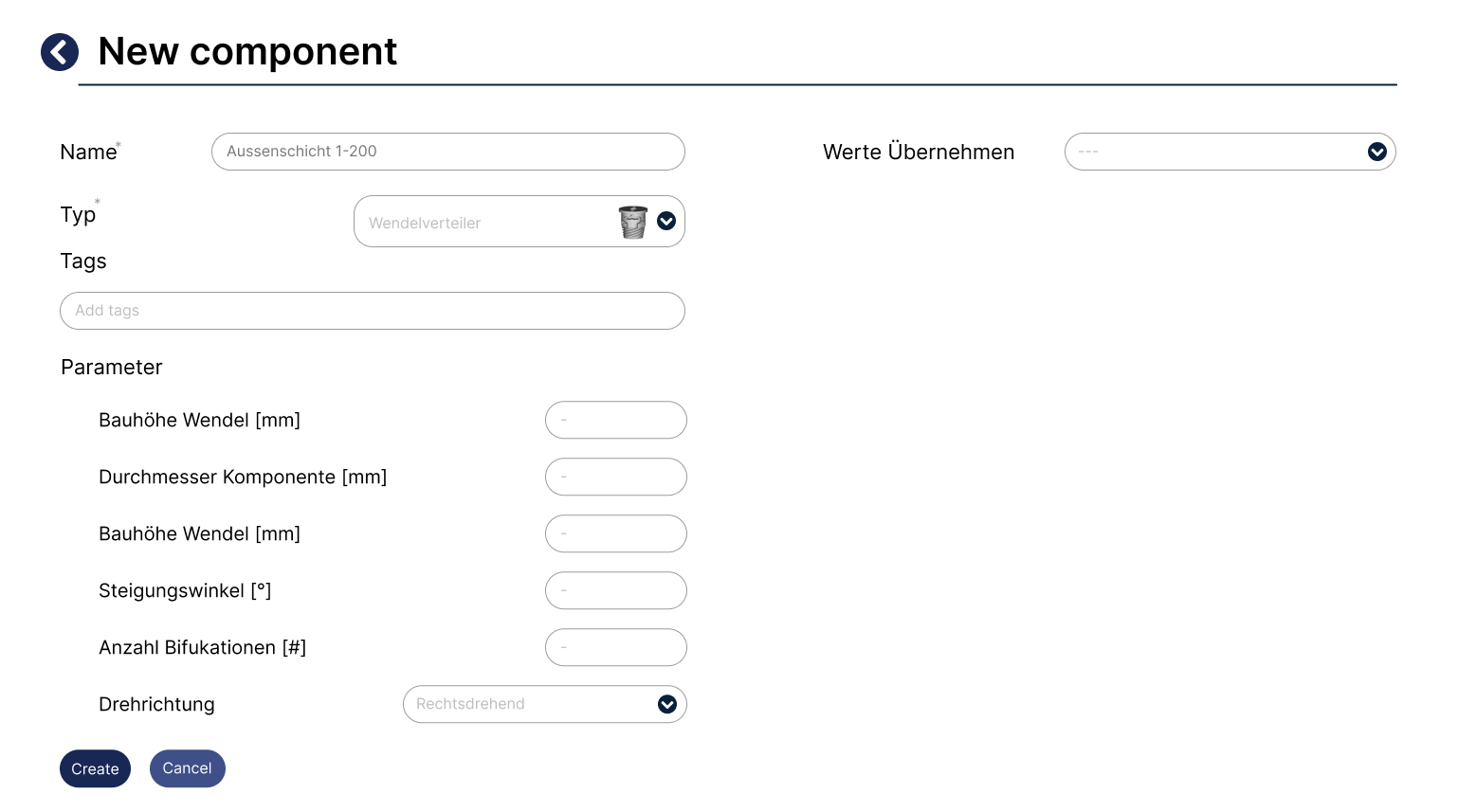
Insert component parameters¶
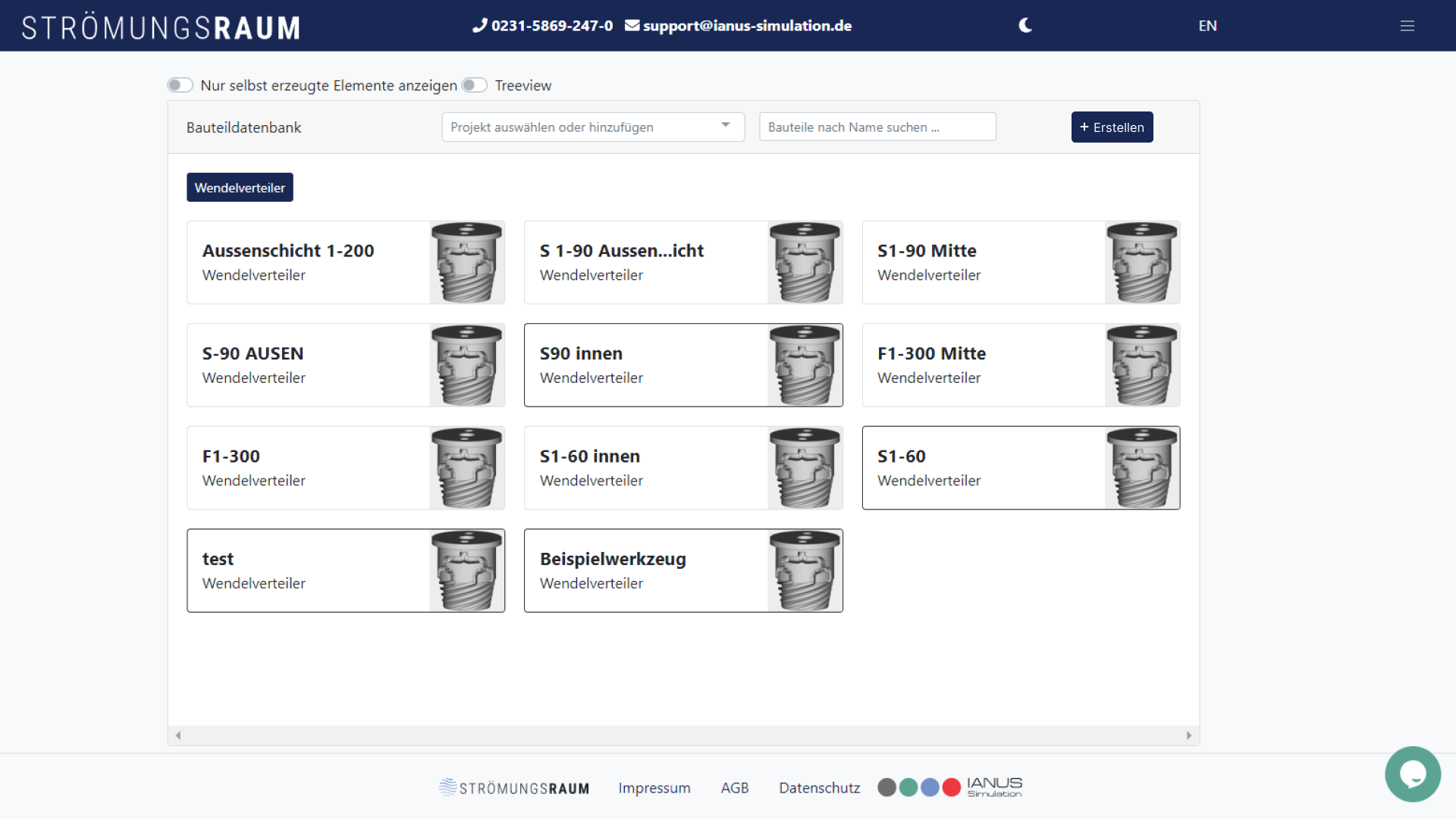
Construction database¶
New simulation¶
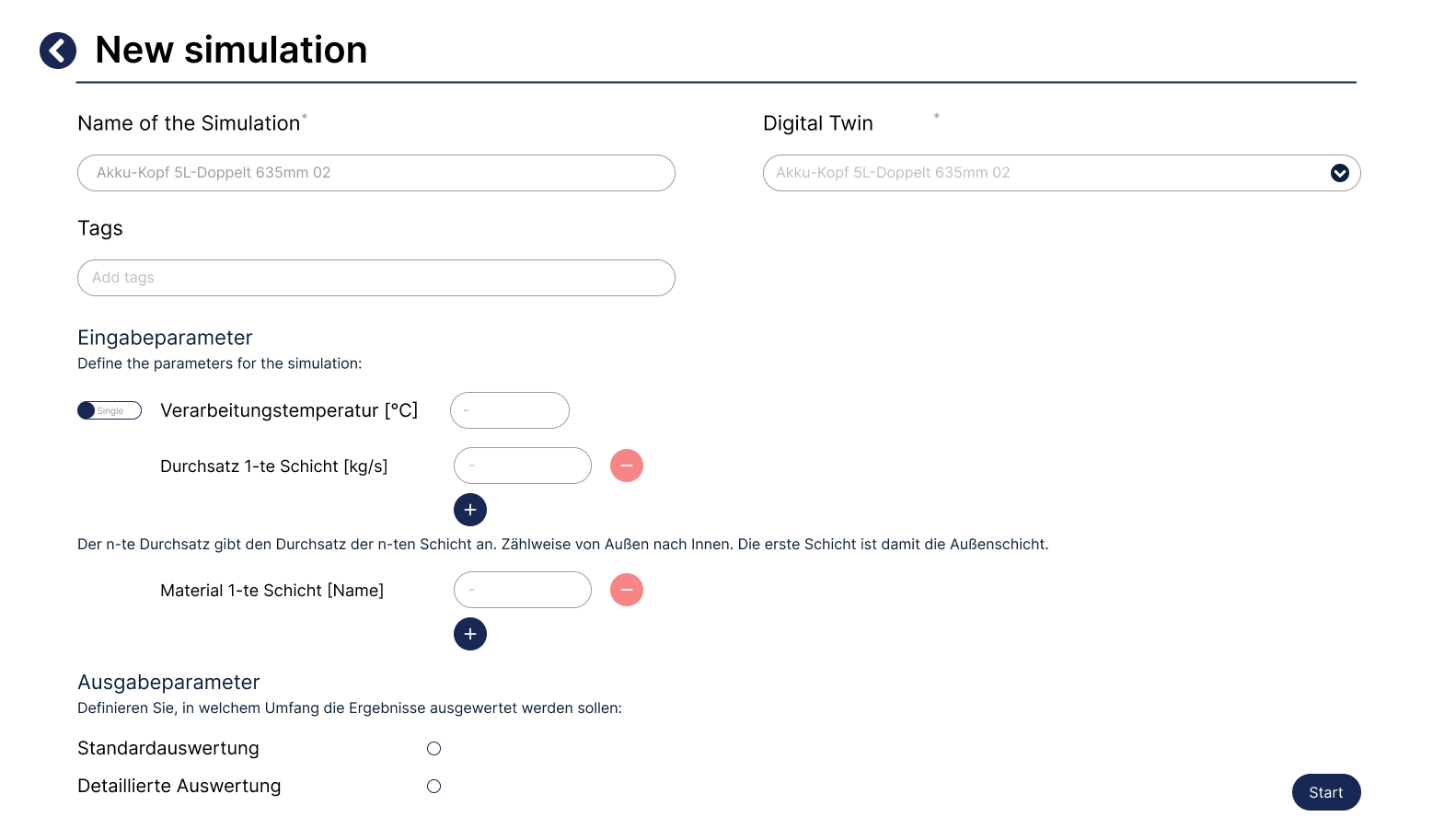
New digital twin¶
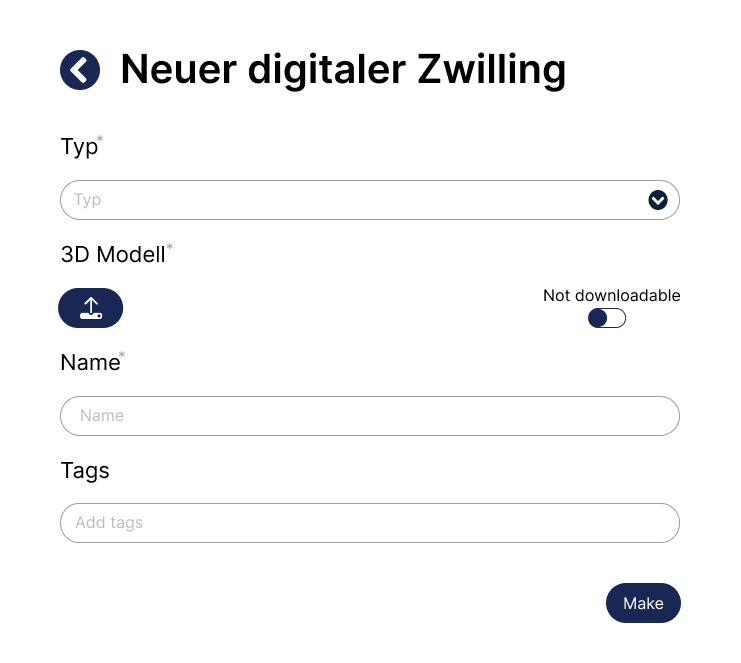
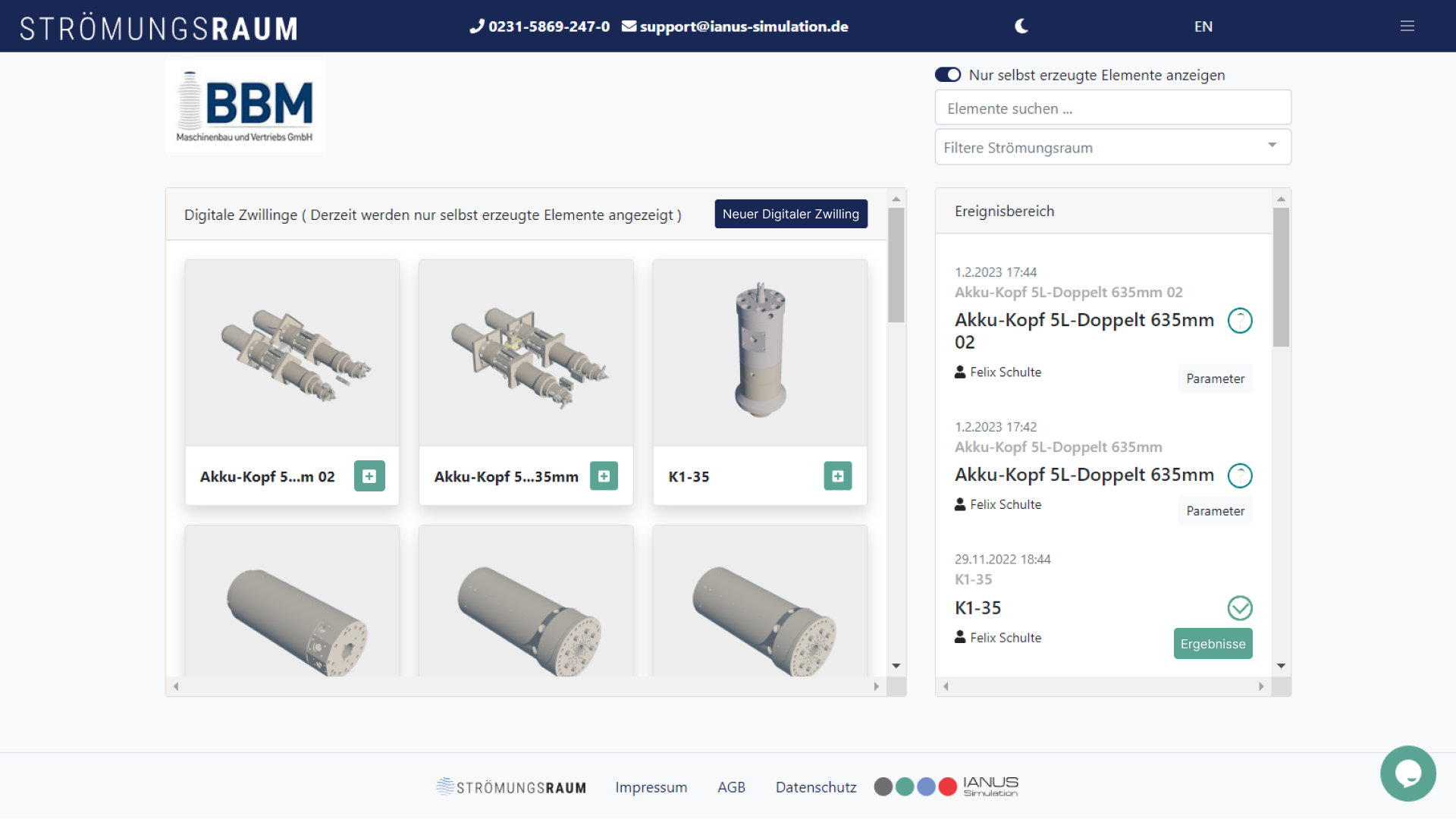
Digital twins¶
Insert parameters simulation¶
Results¶
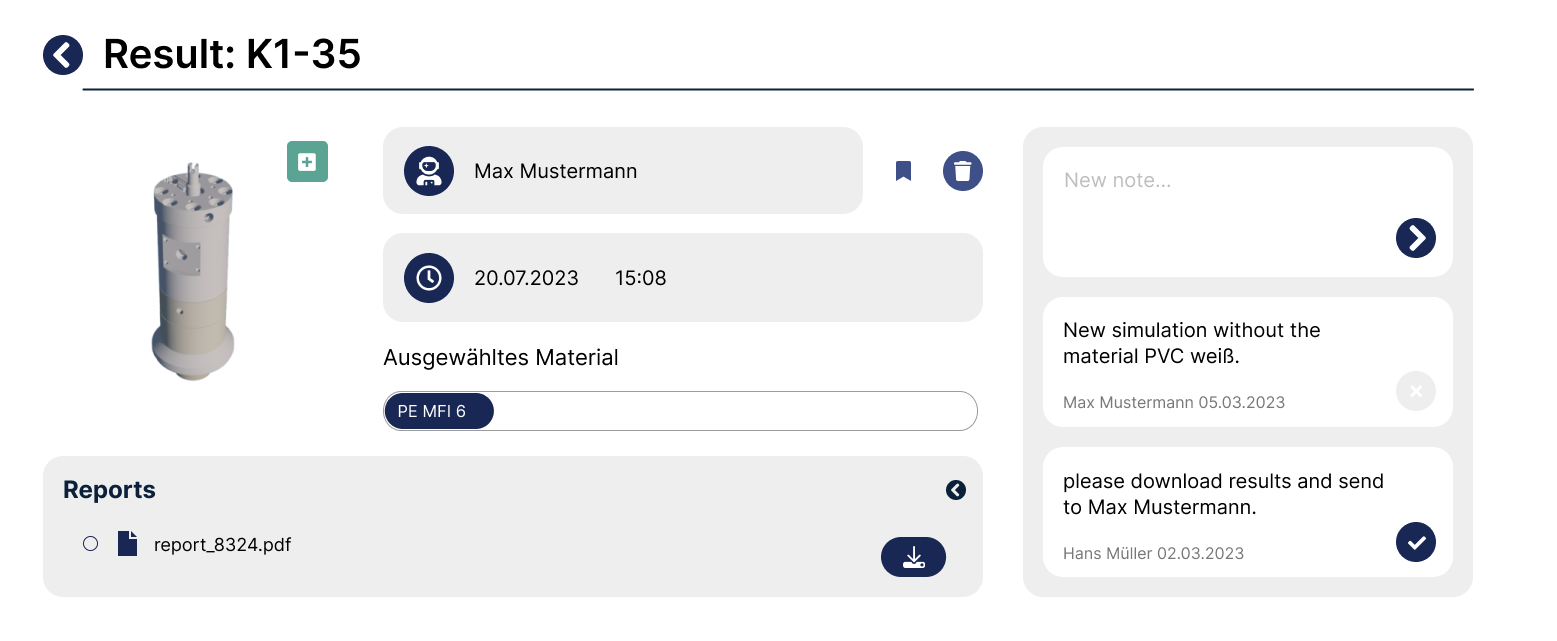
Usage activity diagram¶
The following image depicts the Usage Activity Diagram for the Machine Synthetic Data Generator. Note that Tasks labelled with “Manage” indicate a set of functions that are clustered here for better overview.
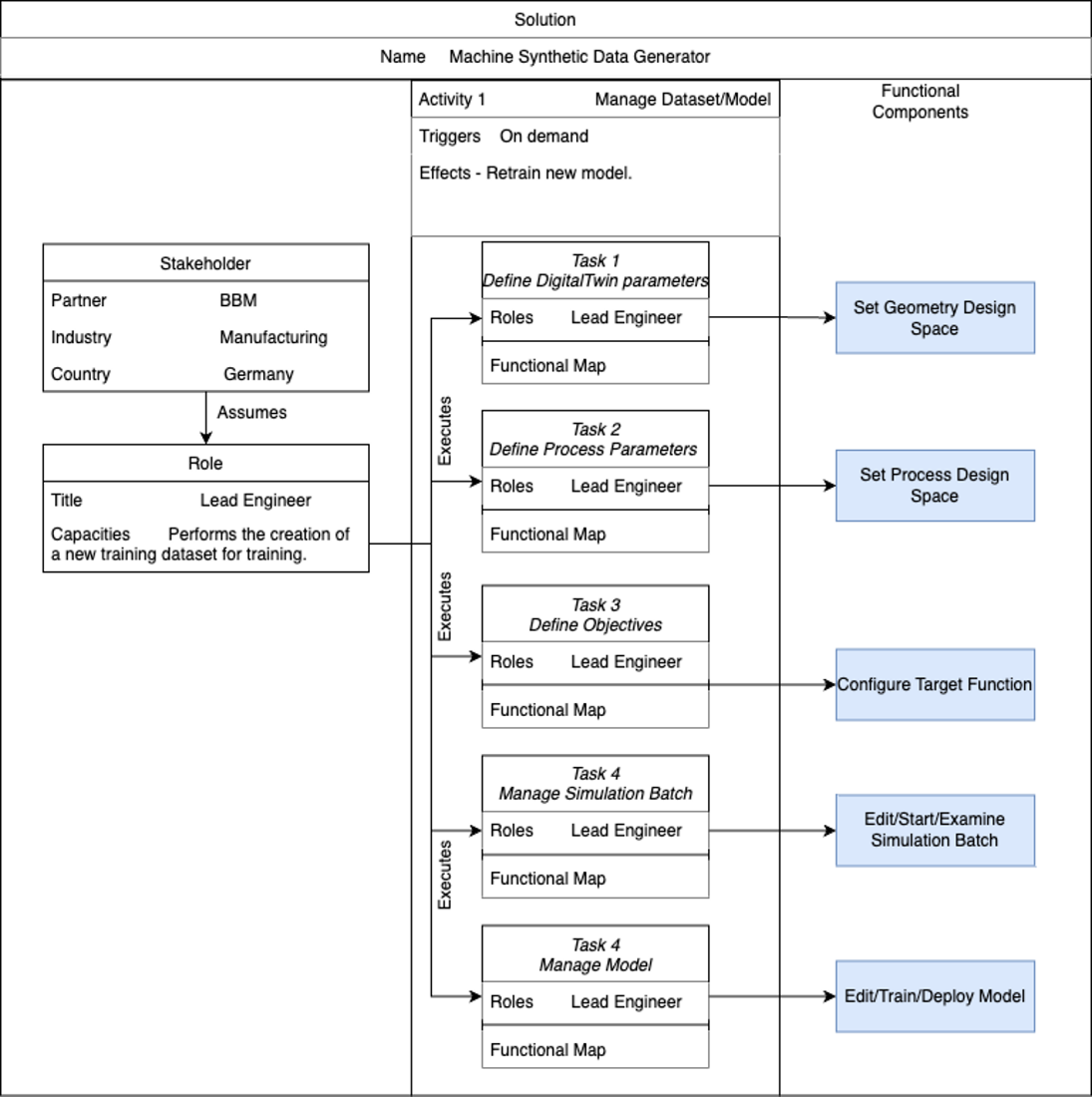
Functional Viewpoint¶
Functional diagram¶
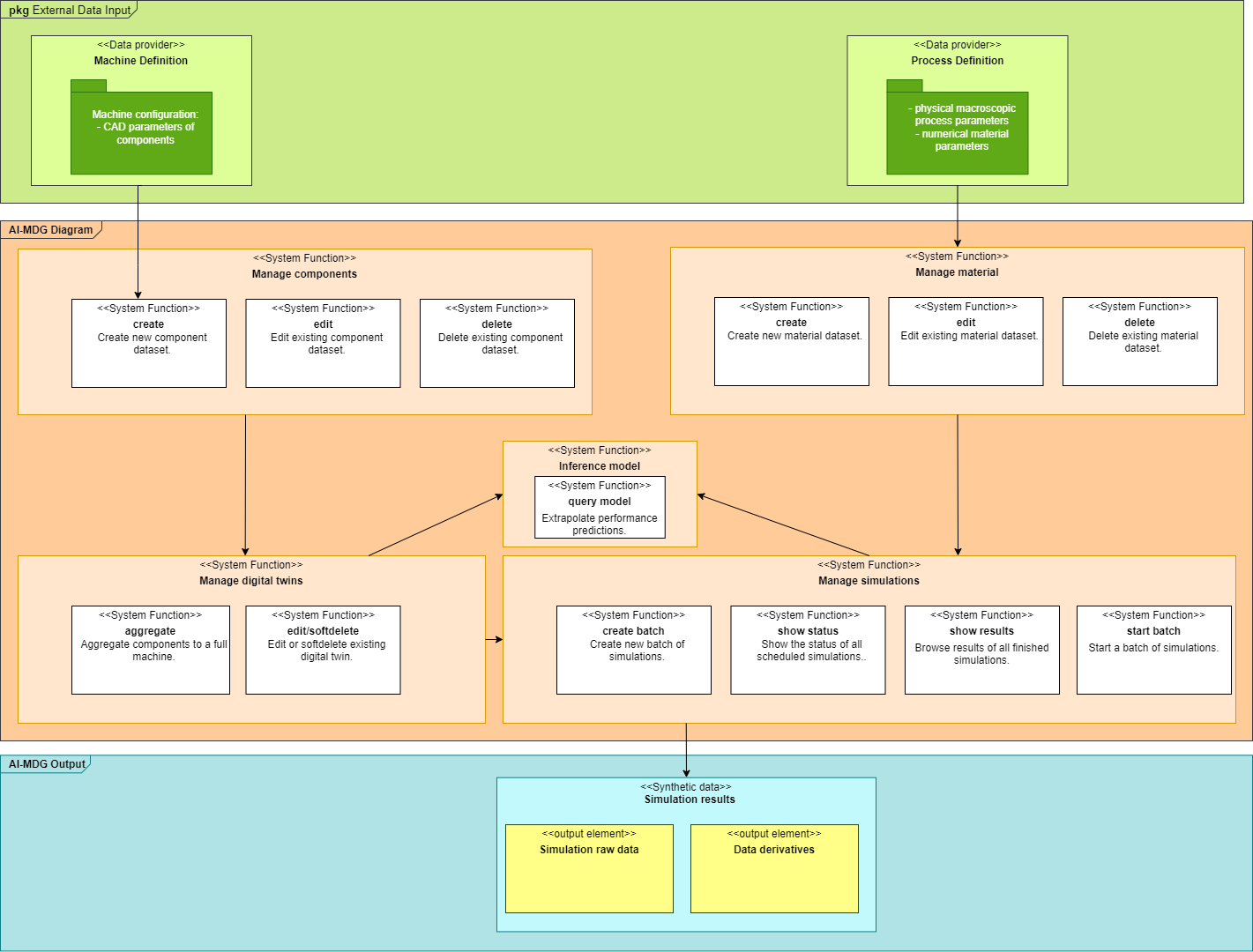
Functional description¶
What: Data generator for synthetic data with physics simulation kernel.
Who: Engineers in a rapid prototyping workflow.
Where: Asynchronously pre-training the AI models.
Why: Generate bulk data and derivatives from simulation for training AI prediction- and generative models where sensor (real-world) data is missing.
Input and output data for each component¶
Manage Component¶
Inputs: Parametric desctiption of the machine part via a fixed parameter set (type: real numbers).
Outputs: 3D CAD model of the machine part, exportable in STEP format.
Manage digital twin¶
Inputs: At least one CAD model(s) from the Manage Component stage.
Outputs: 3D CAD model of the machine, exportable in STEP format.
Manage material¶
Inputs: Base measurements from rheometers or model parameters (type: real numbers) for describing viscosity- and heat properties of the physical fluid and solid materials.
Outputs: Material: Full parameter set for describing viscosity- and heat properties of the physical fluid and solid materials in the underlying PDEs.
Manage sims¶
Inputs: Process parameter ranges (type: real numbers), digital twins from the Manage digital twins stage, materials from the Manage materials stage to define a simulation batch.
Outputs:
A simulation batch ready to be enqueued and executed for result generation.
After burning all so-defined jobs, multi-dimensional result data and data derivatives for training the AI models is available.
Training will be asynchronous to this process.
Inference model¶
Inputs: Simulation batch from the Manage sims stage or a digital twin from the Manage digital twin stage alongside with real numbers describing a process and a material from the Manage material stage.
Outputs: Prediction of performance criteria and/or generative extrapolation of geometric and/or process and material parameters. In general, this is, where the pretrained models will be queried.
Software requirements¶
Software Component |
Description/Role |
Required Version/Configuration |
Dependencies |
|---|---|---|---|
FeatFlower |
Simulation Worker Code. |
Up-to-date checkout. |
ParMetis |
Lifecycle¶
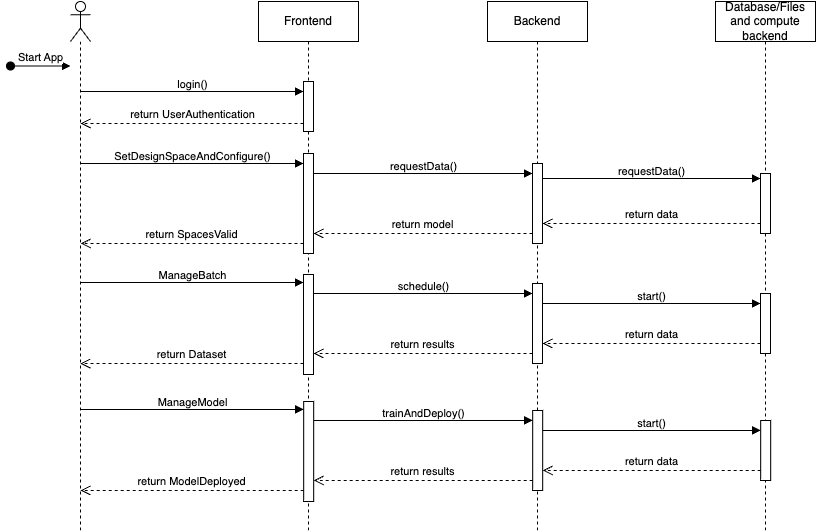
The AIMDG lifecycle is characterised by the lifecycle of configuration, synthetic dataset, and readily trained model.
Objects¶
User: Represents the User interacting with the application.
Frontend: Represents the user interface and the presentation layer.
Backend: Represents the application logic and the server layer. 4.s Database/Files: Represents the data or file storage layer.
Implementation Viewpoint¶
Description of implementation Component:¶
MDG provides support for the integrations of AIDEAS AI-based solutions to generate a Machine synthetic data.
Technical Description of its Components:¶
Dependencies: Development Language:
Python
Libraries: Py Torch, OpenCV, Scikit
Container: Docker
Database need: MongoDB, Postgres
Interfaces:
User Interface: Yes, REACT
Synchronous/Asynchronous Interface: RESTful APIs
Network/Protocols: HTTP/HTTPS
Data Repository: MongoDB
Requires:
Other AIDEAS Solutions: none
Solution architecture¶
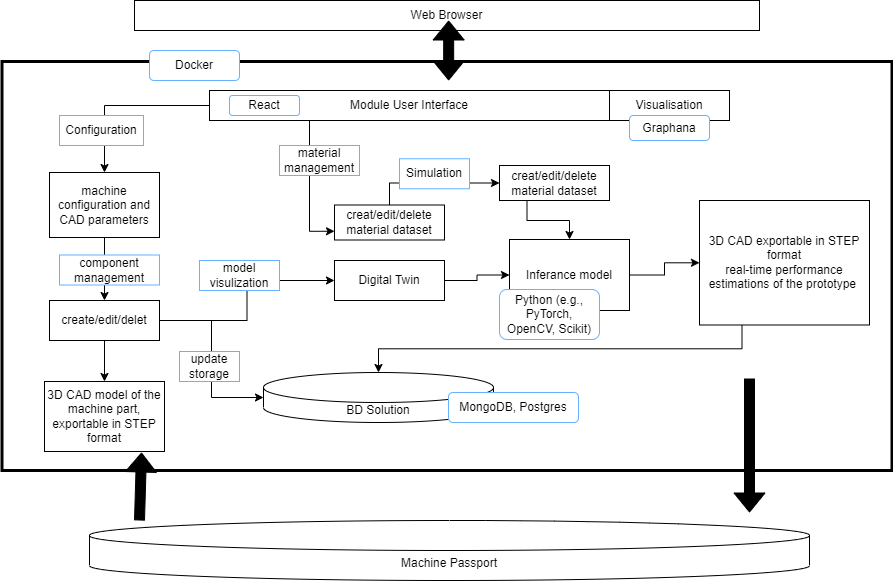
The architecture for the machine synthetic data generator encompasses several components and technologies. The backend development will primarily utilize Python, a widely used language in AI and machine learning, renowned for its extensive libraries and frameworks. PyTorch, an open-source AI framework, will be employed for constructing and training deep learning models. Additionally, scikit-learn, a powerful library, will provide tools for data preprocessing, sampling, and model training, offering a diverse set of machine learning algorithms.
To facilitate data analysis and processing, Pandas will be employed, enabling efficient manipulation and analysis of data. Simulation will be enabled through the utilization of digital twin technology, potentially integrating with simulation software such as ANSYS, COSMOL, or OpenFOAM depending on the specific use case.
In terms of data management, structured databases like MySQL or non-structured databases like MongoDB will be employed to ensure efficient storage and retrieval of data. Lastly, for monitoring and visualization purposes, Grafana can be utilized to provide real-time monitoring and visualization of the generated data. Overall, this architecture encompasses a range of technologies and tools to ensure the effective generation, analysis, simulation, and management of synthetic data for machines.