Prescriptive Maintenance (PM)¶
General Description¶
In the AIDEAS Prescriptive Maintenance solution, the identification of variables related to the remaining component life is crucial for predicting maintenance requirements and extending the useful life of the machine. The solution leverages AI regression algorithms to analyze and process these variables and generate features that are characteristic of the remaining life of the components. To predict the remaining life of the components, the AI regression algorithms use these features as inputs and estimate the remaining life based on historical data, maintenance reports, physics-based models, or a combination of these sources. It’s important to ensure the availability of good regressands, which are the actual remaining life values of the components, for training the algorithms. These regressands can be obtained through experiments, operational data, or other reliable sources. The AI regression algorithms learn from the available data and build predictive models that can estimate the remaining life of components in real-time. By analyzing the predicted remaining life and comparing it with the desired extension of the machine’s useful life, maintenance requirements can be identified. This proactive approach allows for timely maintenance interventions, optimizing machine performance and minimizing downtime. Furthermore, the AIPM solution facilitates a shift to Service-Oriented Business Models that enable offering maintenance services or extended warranties to customers based on the predictive maintenance capabilities. By providing reliable and efficient maintenance solutions, businesses can maximize the value and lifespan of their machines, ensuring customer satisfaction and reducing overall costs. Overall, the combination of AI regression algorithms, data analysis, and Service-Oriented Business Models in the AIDEAS Prescriptive Maintenance solutions enables prediction of component remaining life, proactive maintenance planning and the exploitation of these techniques for machine reuse and long-term value creation.
Usage Viewpoint¶
Use Model¶
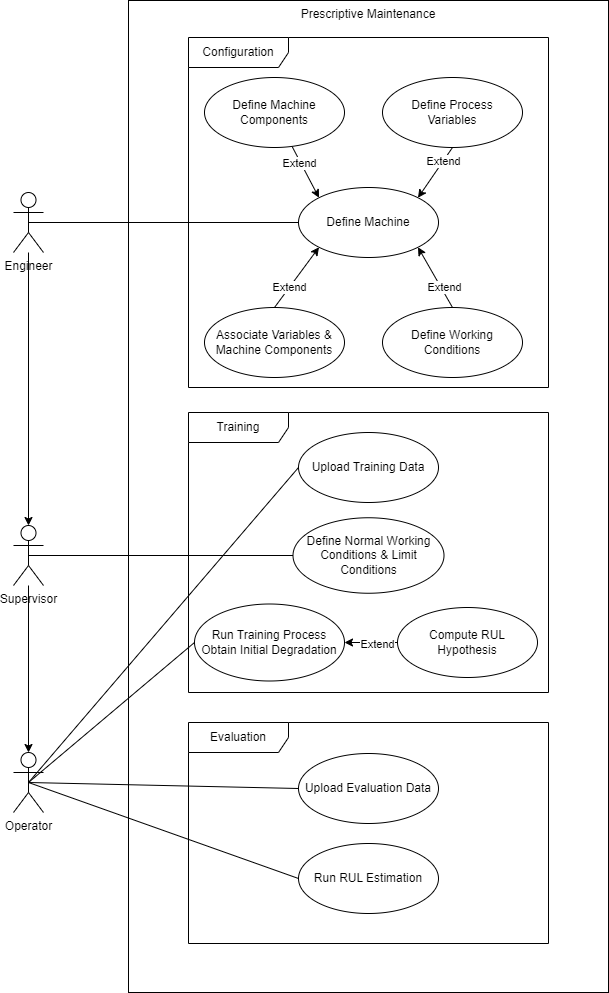
Description¶
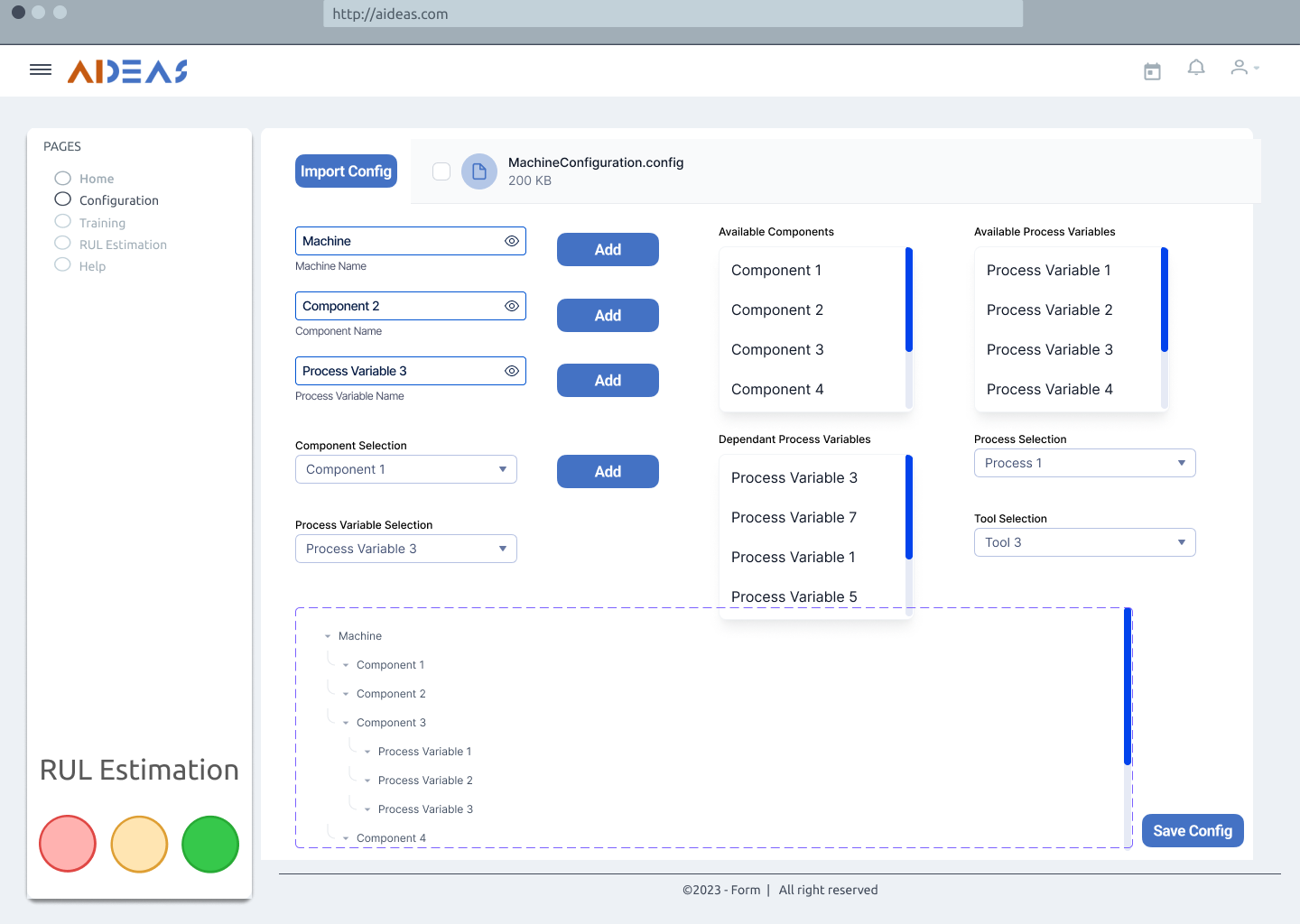
The deployment of Prescriptive Maintenance begins with the machine configuration step, which requires the involvement of an engineer to ensure accurate definition of the machine and its components. The following tasks are involved in this step:
Defining Machine Components: Identify and define the different relevant zones or components of the machine that will be studied. This division helps in focusing on specific areas of analysis and maintenance.
Identifying Process Variables: Determine the process variables that are relevant to the machine’s operation, such as temperatures, currents, pressures, speeds, and other relevant measurements. These variables provide insights into the machine’s behavior and health.
Associating Variables with Components: Establish the association between the process variables and the machine components they directly affect. This mapping helps in understanding which variables impact specific components and enables targeted monitoring and analysis.
Additionally, it may be necessary to define working conditions that provide contextual information about the machine’s operation. This can include factors such as the tool being used, the specific processes being performed, or conditions indicating whether the machine is idle or in operation.
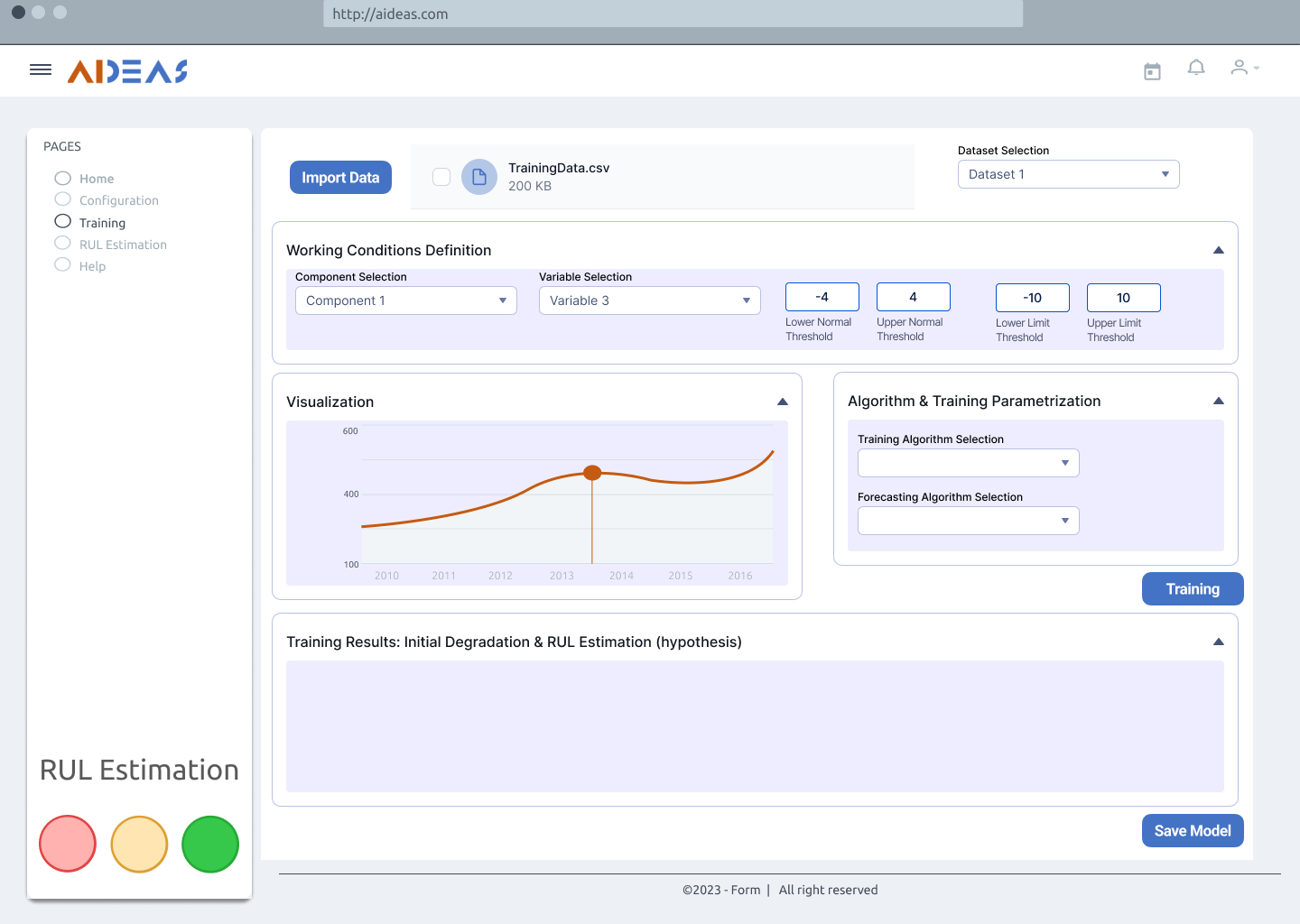
Once the machine is properly defined, the model training process begins, requiring collaboration between the supervisor and the operator. The steps involved in this process are as follows:
Defining Normal and Limit Conditions: The supervisor sets the normal working conditions and defines the threshold values for each process variable that indicate proper machine behavior. They also establish limit conditions that represent thresholds beyond which the machine or its components may experience failure or breakdown.
Obtaining Training Data: A dataset is required for training the machine learning model. This data can be obtained from files or a database and should include historical information about the machine’s behavior and associated process variables. The desired algorithm and its parameters are also determined at this stage.
Setting Remaining Useful Life (RUL) Hypothesis: The supervisor establishes the RUL hypothesis for each process variable, which determines the remaining useful life estimation for the components based on their current conditions and historical data.
Training the Model: The training process involves feeding the dataset into the chosen algorithm with the specified parameters. The model learns from the data and establishes relationships between the process variables and the remaining useful life of the components.
In the evaluation process, the operator continuously performs tasks to obtain RUL estimates for the entire machine or specific components. The solution provides insights into the remaining useful life, allowing for proactive maintenance planning. It’s important to note that the tasks performed by the operator can also be carried out by the supervisor or higher-level users, depending on the hierarchy within the organization.
By following these steps, the Prescriptive Maintenance solution enables effective machine configuration, model training, and ongoing evaluation of the remaining useful life, facilitating proactive maintenance and optimization of machine performance.
Home page¶
Configuration¶
Training data¶
RUL estimation¶
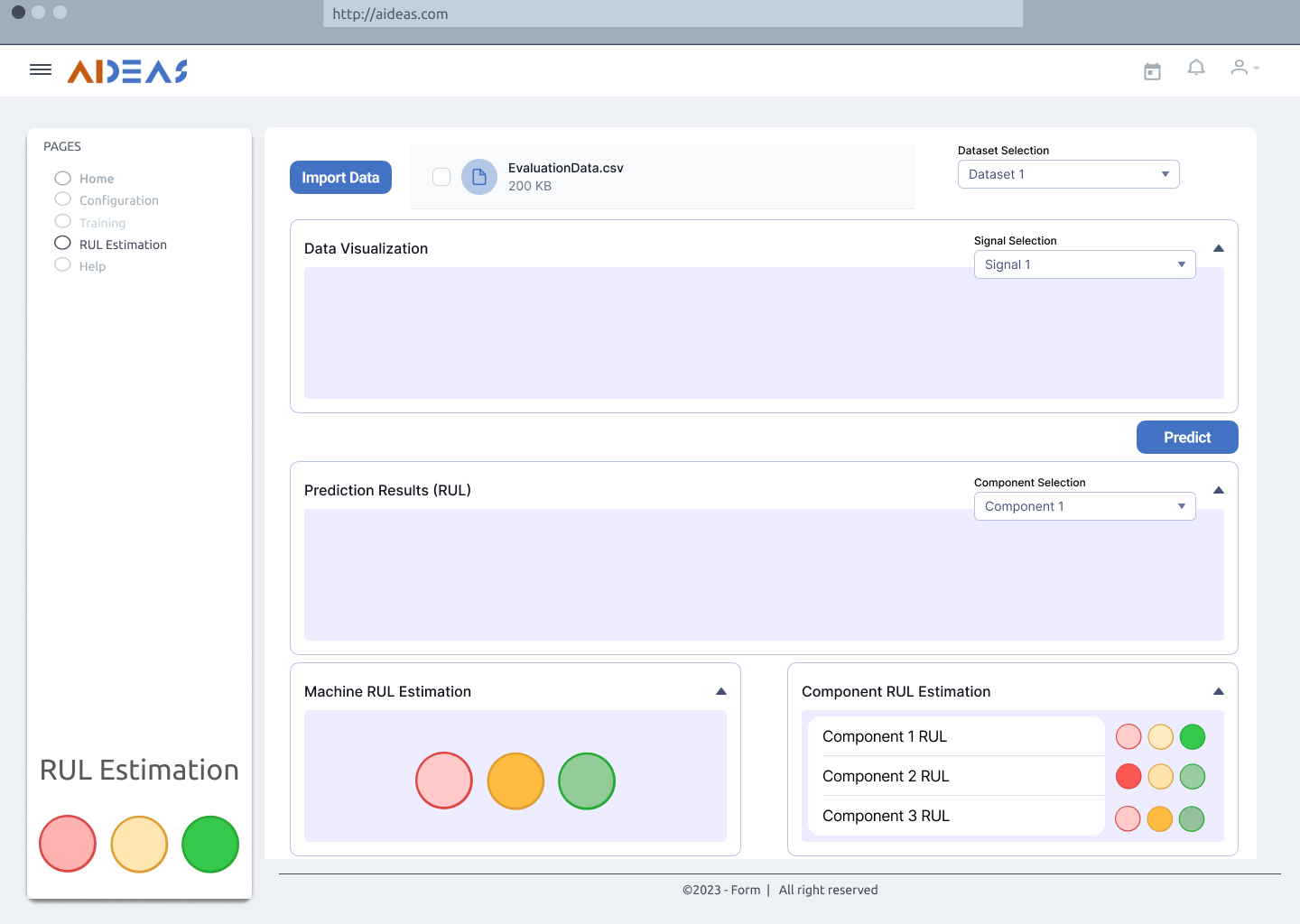
Usage activity diagram¶
The following image demonstrates the interaction between the different tasks and roles. No pilot distinction is made as these are the same independent of the use case. This diagram illustrates the dynamic flow of interactions, offering a representation of the activities executed by the solution providing a clear understanding of the activities executed using the AIPM solution.
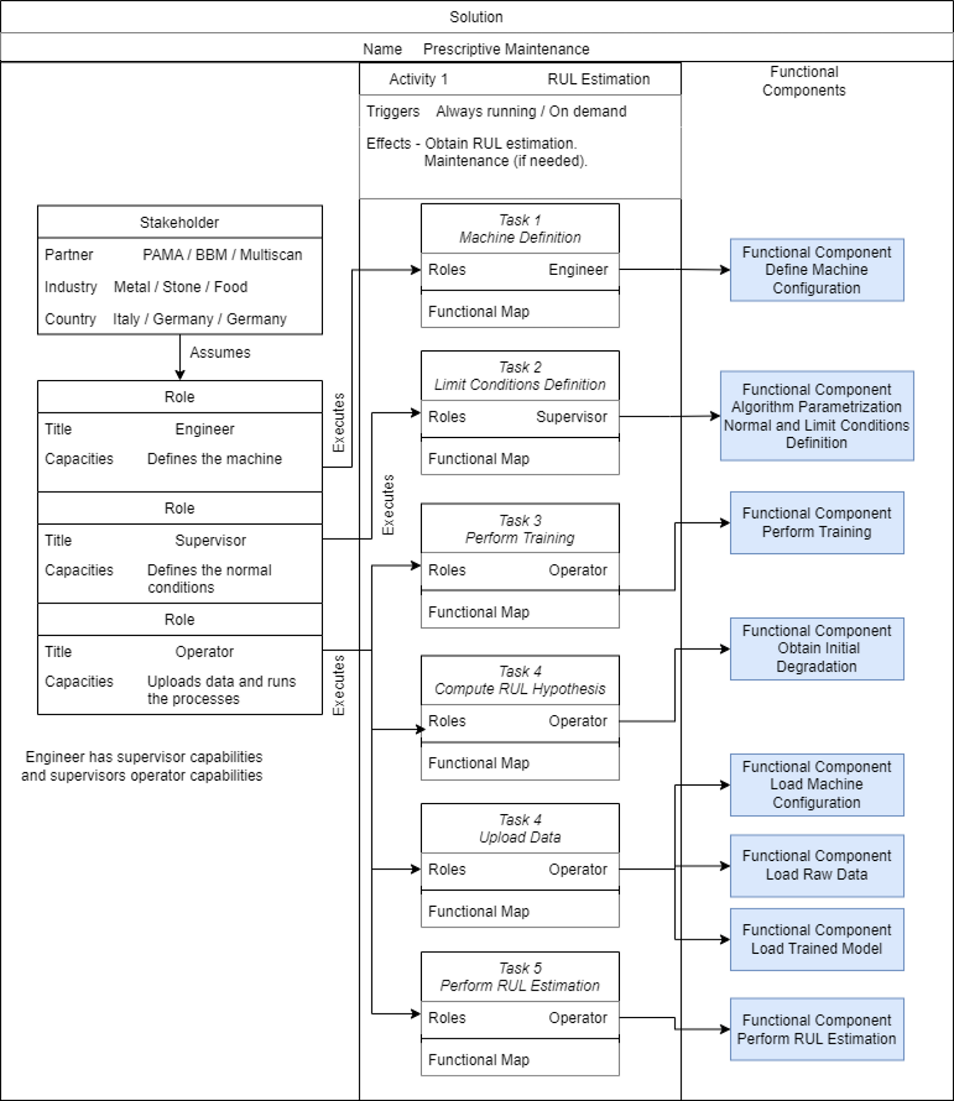
Functional Viewpoint¶
Functional diagram¶
Functional description¶
What: The main feature of this component is to get an estimation of the remaining useful life of the machine, in which is deployed, or in any of its components. This RUL estimation could be computed in pseudo real time.
Who: Process Engineer. Maintenance Manager. Operator.
Where: Platform Tier.
Why: To obtain RUL estimation of the machine or any of its components.
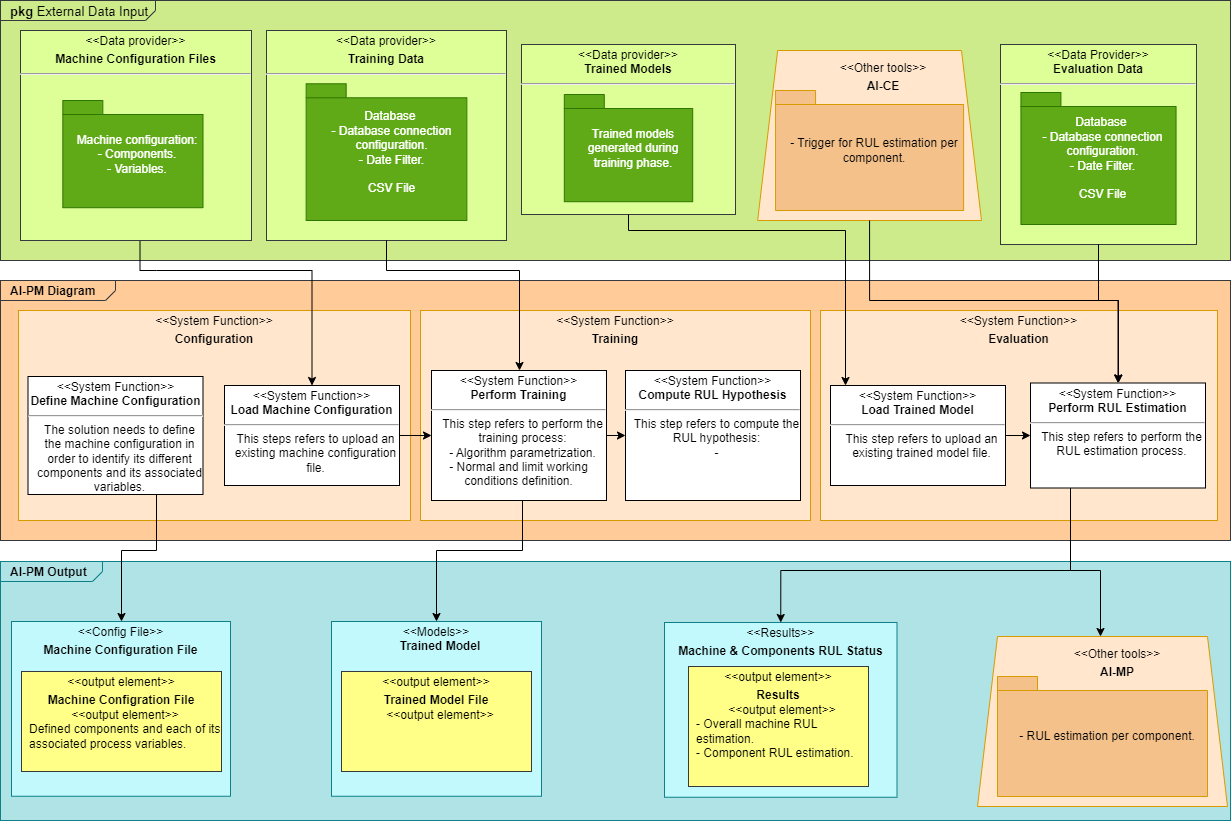
Input and output data for each component¶
Define Machine Configuration¶
Inputs:
Machine – machine in which the solution is deployed.
Components – every subset of elements that define the machine.
Variables - each process variable that exist in the use case. Variables such as: speed, current, pressure, flow, temperature, …
Dependencies – relation between components and process variables. They define which process variables have a direct effect in a specific component.
Tool – if there are different tools.
Process - if there are different processes carried out by the same machine.
Outputs:
Machine configuration file – its extension may vary depending on the machine in which will be deployed. Its format will be standardized independently of the solution, and it could be a JSON or xml file.
Load Machine Configuration¶
Inputs:
Machine configuration file generated.
Outputs:
Configure machine viewed as a hierarchy tree with the following levels:
Machine.
Component.
Process Variable.
A List with the relationship between component and variables.
A list of the different tools used.
A list of the different processes.
Perform Training¶
Inputs:
Training data – set of data gathered from a database or uploaded from a csv file.
Algorithm selection and parametrization – the desired algorithm must be selected, from a list, and parametrized.
Normal and limit thresholds – normal and limit working conditions must be defined with a set of thresholds indicating good operating threshold and limit operating thresholds before a component breaks down.
Outputs:
Trained Model – once the training process has finished, a model could be downloaded from the frontend to be used as an input for the evaluation process. Model file extension is yet to be defined.
Compute RUL Hypothesis¶
Inputs:
Training process and forecasting algorithm results.
Outputs:
RUL hypothesis results based on the fitting function used.
Load Trained Model¶
Inputs:
Model trained and generated during training phase.
Outputs:
Trained model statistics.
Perform RUL Estimation¶
Inputs:
Evaluation Data - set of data, different from the training data, gathered from a database, periodically, or uploaded from a csv file.
Outputs:
The output may vary depending on the consumer of the results generated with this tool:
Machine in which the solution is deployed: the overall machine RUL estimation as well as RUL per component will be given. Data could be written directly to a database or could be downloaded by the user from the frontend.
AI-MP: component RUL estimation will be given.
Software requirements¶
Software Component |
Description/Role |
Required Version/Configuration |
Dependencies |
|---|---|---|---|
Linux OS or Windows OS |
Operating system needed to use the tool |
Ubuntu 22.04 / Windows 10 Pro |
N/A |
Docker |
Build, share and run containers |
latest |
N/A |
Lifecycle¶
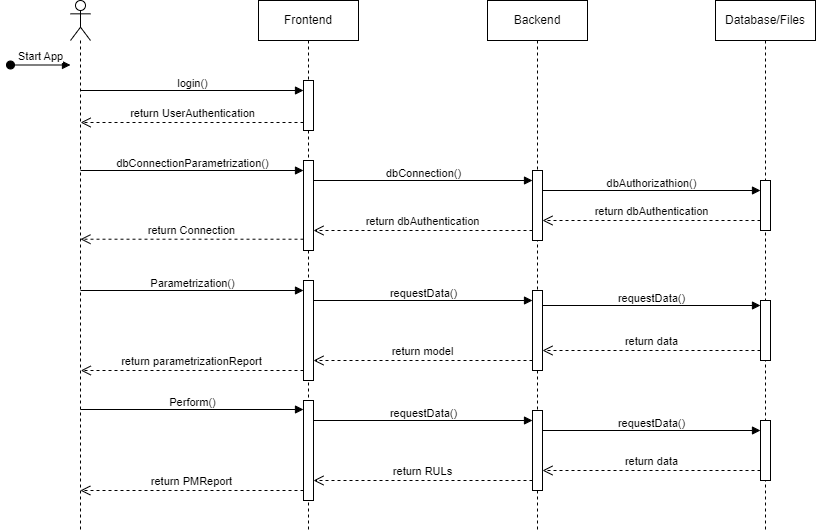
This sequence diagram illustrates the flow of interactions between the User, Frontend, Backend and Data/Files objects during the main processes. Login into the AIDEAS platform, parametrize a connection to an external database, parametrize the anomaly detection and perform it.
Objects¶
User: Represents the User interacting with the application.
Frontend: Represents the user interface and the presentation layer.
Backend: Represents the application logic and the server layer.
Database/Files: Represents the data or file storage layer.
Implementation Viewpoint¶
Description of implementation Component:¶
AI-PM is a toolkit for anomaly detection at both machine and component levels.
Technical Description of its Components:¶
Dependencies:
Development Language: - Python.
Libraries: NumPy, Pandas, SciPy, Keras, Py Torch, TensorFlow.
Container: Docker.
Database need: MongoDB.
Interfaces:
User Interface: Yes, REACT.
Synchronous/Asynchronous Interface: RESTful APIs.
Network/Protocols: HTTP/HTTPS.
Data Repository: MongoDB.
Requires:
Other AIDEAS Solutions: AI-CE (used as a trigger to know when abnormal behaviour starts).
Solution architecture¶

That sounds like a well-designed architecture for the AI-PM system. Here’s a summary of the technologies and components involved:
Backend Development:
Programming Language: Python
Libraries: NumPy, Pandas, SciPy, Keras, PyTorch, TensorFlow
Framework: Flask or Django (common web frameworks in Python)
Data processing: NumPy for array and matrix operations, Pandas for data analysis and manipulation
Machine Learning: SciPy, Keras, PyTorch, TensorFlow for training and evaluating ML models
RESTful API: Flask or Django can be used to build the API endpoints
Database: PostgreSQL or any other suitable database for storing and retrieving data
Containerization: Docker to package the backend components and dependencies
Frontend Development:
JavaScript Library: React for building the user interface
State Management: Redux for managing the application state
Communication: RESTful API over HTTPS protocols to interact with the backend
Testing: Tools like Postman can be used to test the API endpoints
Containerization and Deployment:
Docker: Used to package the backend, frontend, and their dependencies into containers
Container Orchestration: Technologies like Kubernetes can be used for managing and scaling the containers
By leveraging these technologies, you can develop the backend using Python and relevant data science libraries, while the frontend can be built using React and Redux. The communication between the backend and frontend will be facilitated through a RESTful API, ensuring secure data transmission using HTTPS protocols. Docker can be used to package the entire system into containers, making it easy to deploy and manage.